tl;dr: if a URL’s query params all start with utm_, you do not need to separate them with &. Use the simple &.
Using & when it’s not required is harmless. But it’s not really best practice, since it makes links harder to build by hand and harder to read.
On the other hand, if you use params other than utm_*, might as well stick with &. Knowing exactly which names/prefixes require & is tricky, as we’ll see below. And if you use a URL builder that automatically spits out & that’s fine.[1]
Why you don’t need it with utm_ params
& is the HTML-encoded form of &. You need in only one case: when the characters that follow the & would otherwise be confused for one of HTML’s named or numeric entities.
This is not the case with with utm_ params because there’s no named entity &u, &ut, or &utm. (Named entities only contain letters, so once you get to _ you can stop worrying.)
HTML has a standard list of 2200-odd named entities that’s guaranteed to never grow. Follow the link for the full entity list; the important part is here, the last stretch that starts with u:
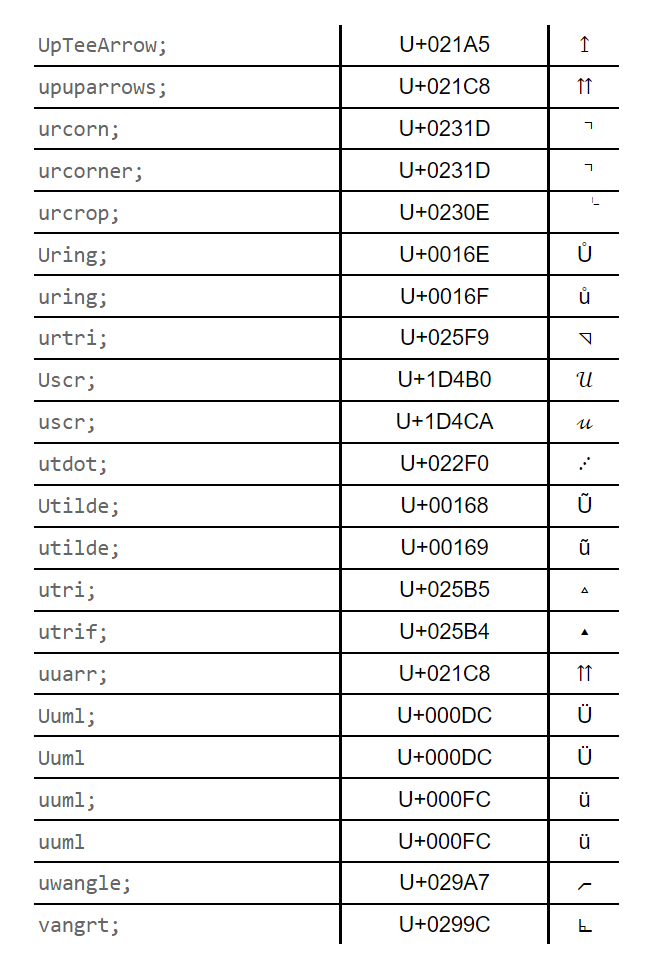
As you can see, none match any part of utm. So there will never be a case where &utm is interpreted as anything other than the 4 characters &, u, t, and m. That’s why you don’t need &utm.
When you do need &
When you use & (or, to make things more confusing, just & without the semicolon) the HTML parser treats that 4- or 5-character sequence as an encoded name — like a macro — for the single character &.[2]
That ability to HTML-encode & — to ensure it’s a literal & — can be critical.
Let’s say your website uses a query param current_language, like current_language=en or current_language=fr. That’s very different than utm_, because curren is one of the named entities!

So when you include a querystring-like sequence anywhere in HTML — not just in an <a href>, by the way, but anywhere — and current_language isn’t the first query param, you must use &current_language instead of ¤t_language.
If you use the simple &, ¤ will be parsed as the named entity and turned into its underlying character. You’ll end sending people to bizarre URLs like this:
https://www.example.com/landingpage.html?product=laptops¤t_language=en
See what happened there? ¤ was replaced by the generic currency sign ¤. Now you effectively have a single query param product with the value laptops¤t_language=en. Yikes upon yikes.
So & absolutely has its place. It’s just not needed with the standard marketer’s collection of utm_ params.
Notes
[1] Provided those URLs are used in HTML Text or Attribute data. You must not use HTML-encoding (neither & nor &anythingelse;) in CSS <style> nor JS <script> content, nor in the Location bar, nor in tag names, nor anywhere outside HTML.
[2] And that replaced & is disconnected from its following characters, even if they’re in the named entity list. Named entity evaluation is not recursive. That would be a nightmare!
