- Marketing Nation
- :
- Products
- :
- Blogs
- :
- Product Blogs
- :
Your Achievements
Next /
Sign inSign in to Community to gain points, level up, and earn exciting badges like the new Applaud 5 BadgeLearn more!
View All BadgesSign in to view all badges
Stripping the “.html” from Marketo LP hits in Google Analytics
Article Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
Level 10 - Community Moderator
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
01-14-2020
12:42 AM
As you already know (right?) Marketo-hosted Landing Pages can be accessed with or without a trailing .html in the path part of the URL.[1]
So these URLs are aliases for the same content:
https://pages.example.com/myoffer?utm_medium=email
https://pages.example.com/myoffer.html?utm_medium=email
From a Marketo perspective, then, it’s merely a cosmetic choice. (Personalized URLs are an exception, which I’ll explain in the notes.[2])
However, when you add 3rd-party trackers like the ubiquitous Google Analytics, those packages can’t know out-of-the-box that the URLs are equivalent. As far as GA knows, your webserver may well treat them differently: they are, after all, different URLs.
(/myoffer.html, /myoffer.rss, /myoffer.json etc. could deliver very different content. Some web apps use resources differentiated only by their “extension” to switch content types.[3] The extension-less /myoffer would probably be an alias for one of the types, but GA couldn’t know which one.)
With Marketo knowledge in hand, you’ll want to bridge the gap in GA so hits are combined. Otherwise, you see reports like this:

Since this was a Marketo LP, you know there were only 3 unique pieces of content at maximum loaded, but GA recorded 5 different URLs because it couldn’t know better.
Note: I’m not talking about query parameter removal. That’s another, well-covered matter, and GA has a built-in feature for it. For today, treat ?foo=bar and ?foo=baz as if they displayed substantively different content to the end user (perhaps via runtime segmentation). When that doesn’t apply to your LPs, you should also use Exclude URL Query Parameters. But today is about Marketo showing the same content with or without .html at the end of the path.
Valiant, and not so valiant, efforts
Many people have written so-called HOWTOs for this task. As far as I can see, zero of them are correct.[4] Distressingly, include Google’s own docs in the “incorrect” category.
All the authors knew to use a Search and Replace filter in the Analytics console. (With some, their knowledge stopped there.)
Most attempts are almost-right, but show the telltale sign that the author doesn’t actually know what constitutes a valid URL.
That’s the thing: even if you’re a regular expression expert, like truly world-class (which I do not claim to be), that doesn’t help if you’re wrong about what you need to match! Unless a regex is pathologically inefficient, a clunky-but-correct one is fine… a slick-short-but-wrong one is never OK.
Anyway, here’s a take I’ve suggested myself, to my shame:

If you can’t read the screenshot, that’s:
Search String: \.html(\?|$)
Replace String: \1In English-ish:
Search for the character sequence “.html” when it’s immediately followed either by the question mark symbol “?” or by the end of the string.
Replace whatever you found with just the question mark (if you originally found a “?”) or with the end-of-string anchor (if there was no “?”).[5]
Sounds right, eh? A question mark starts the query string. So the expression finds .html right before the query string, i.e. at the end of the path. When there is no query string, it finds .html at the very end of the URL. Then it chops what it found out of the string, without changing anything else.
Apply that filter and you indeed get a cleaner report like this, which will strip the .html in the path and group pageviews accordingly:
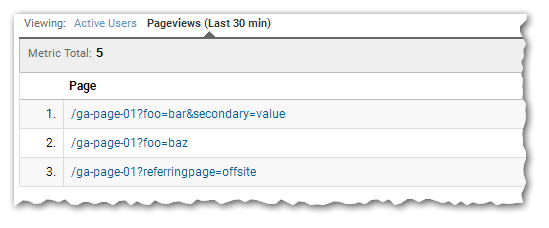
But something ain’t quite right.
What’s missing
Look closer at the above screenshot. Page 3, after filtering, is:
/ga-page-01?referringpage=offsite
Problem is, the page the user actually viewed was
https://pages.example.com/ga-page-01.html?referringpage=offsite.html
Oops. You stripped the .html from the path, yes. But you also mistakenly stripped the .html from the query string.
“A filename in the query string?” you ask. Sure, why not? It’s completely valid, and might contain valuable information about lead attribution. By inadvertently affecting the query string, you could change the meaning of the person’s journey.
“OK,” you say, “but that only happened because it was at the very end of the query string. It couldn’t happen in the middle of the query string, because the query can’t have a question mark inside it.”
Oh yeah?  Check out this (completely valid) URL:
Check out this (completely valid) URL:
https://pages.example.com/ga-page-01.html?referringpage=offsite.html?linkedin&referringplacement=89607“Wha? Two question marks?”
Absolutely. The URL standard (RFC 3986) says the ? character delimits (separates) the path or hostname part from the query part, but only when the ? appears in a particular position. And after that position, it’s possible to have a literal (unescaped) ?. So you can have another ? in the query string itself.
You can also have, to name a couple of other surprises, a : in the query string (not just in the protocol) and slashes in the query string (not just in the path). https://www.example.com/?:a/?:b/?:c/?:d is a valid URL – one almost guaranteed to confuse, but valid.
Forget Expand what you know about delimiters
The key is that delimiter characters in a URL don’t work the same as delimiters in, say, a CSV. The CSV delimiter , keeps its special meaning across multiple occurrences:
First Name,Last Name,Company,Email Address,City,State,Postal CodeIn contrast, the delimiters in a URL lose their special meaning based on whether they’ve already been used once and/or if they’re in a non-special position. The rules are too complex to be reviewed here, but you should read the RFC.
Such details are why writing your own URL parser is by no means easy. Many little pieces of code out there are broken, because they naïvely split on delimiters without looking at the order of delimiters.
Getting it right(er)
Now we know to not only anchor the .html just before a ?, but also to make sure it’s the first ? in the URL.
Like so:
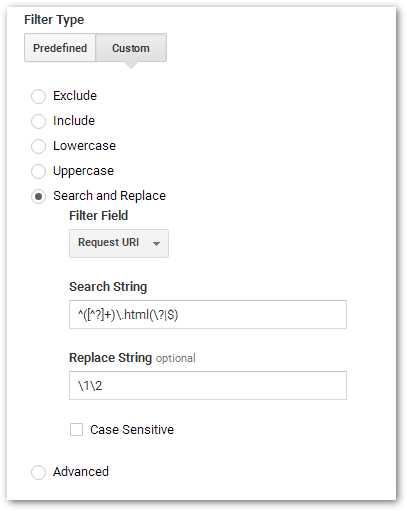
Plain text:
Search String: ^([^?]+)\.html(\?|$)
Replace String: \1\2English-esque:
Search for the sequence “.html” when it (a) follows a block of text, *starting from the beginning of the string,* that’s at least 1 character long and has no “?” symbols and (b) is immediately followed by a “?” symbol or by the end of the string.
Replace what you found with the text before the “.html” (whatever it was) concatenated with the text after the “.html” (if any).
Now we properly strip only the .html that was at the end of the path:
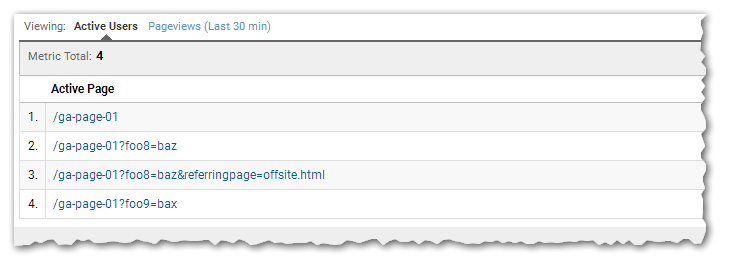
I still left out the #hash (URL fragment)
By default, GA won’t track the #hash part of your URLs at all. And if you are using the #hash meaningfully (say, in an older-school Single-Page Application) your web developers will have already worried about it and figured out the right custom GA hits + filters.
But… in the interest of completeness, it’s also possible for the string .html to appear in the URL fragment:
https://pages.example.com/mypage.html#ref:pageonsomeothersite.htmlThe “right(er)” regex above will erroneously truncate pageonsomeothersite.html to pageonsomeothersite in the hash – like how the initial regex mistakenly trimmed .html in the query string. For full coverage, change your regex to:
^([^?#]+)?\.html(\?|#|$)If you followed the regex breakdown above, this should make sense.
Notes
[1] Yes, I’m being super-precise – the URI standard has no concept of a “filename,” just the /slash/separated/part known as the path. The path might have one or more segments that happen to look like files in a filesystem. One of those might correspond to a physical file on the server, but doesn’t have to.
[2] When you use pURLs, you can’t use the .html extension and the Marketo Unique Code/Marketo Unique Name at the same time. You have to use the extension-less form, https://pages.example.com/offer/XYXPDQ.
[3] Admittedly, those are usually service or API URLs and not the main URL in the Location bar. But you never know, and the safest bet is to assume URLs are different for a reason. Note response type switching is more RESTfully done using the Accept: header, but that only works where it can be customized.
[4] To be fair, most of the authors are SEO mavens by trade, so they cross-publish – and some suggestions are outright stolen – so there really isn’t much original content.
[5] Re-replacing the end-of-string $ doesn’t actually do anything, as it’s just a position.
4 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- Copyright © 2025 Adobe. All rights reserved.
- Privacy
- Community Guidelines
- Terms of use
- Do not sell my personal information
 Adchoices
Adchoices